单变量回归问题
我们将使用一个变量实现线性回归,根据城市人口数量,预测开小吃店的利润,数据在ex1data1.txt里,第一列是城市人口数量,第二列是该城市小吃店利润。
读取数据
利用pandas读取数据,并显示前5行数据检查是否读取成功。
1 | import pandas as pd |
| Population | Profit | |
|---|---|---|
| 0 | 6.1101 | 17.5920 |
| 1 | 5.5277 | 9.1302 |
| 2 | 8.5186 | 13.6620 |
| 3 | 7.0032 | 11.8540 |
| 4 | 5.8598 | 6.8233 |
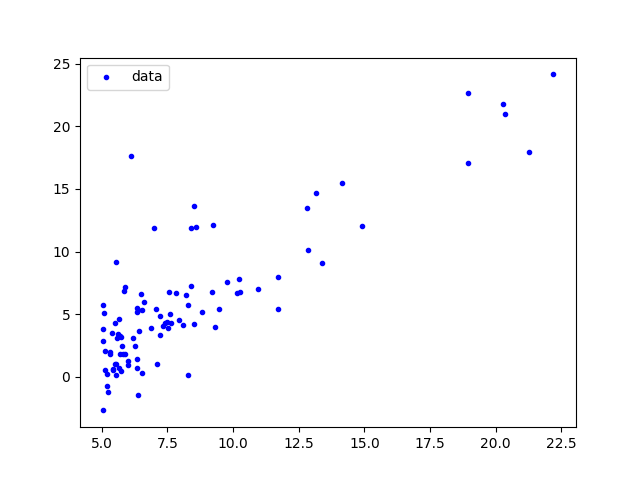
数据可视化
第一步我们需要对数据进行可视化,初步判断数据之间是否存在线性关系,这对后面的分析十分重要。
1 | import matplotlib.pyplot as plt |
数据处理
根据吴恩达课程所讲,我们需要在x的第一列加上一列x_0=1,初始化初值为0的theta。
1 | import numpy as np |
代价函数
采用回归问题中常用的平方误差代价函数。
其中
注意在前面初始化的时候添加了一列x_0,故
我们的目标是求出能够最小化J(θ)的θ,这样预测值才能更加接近y,即:
1 | import numpy as np |
得出的结果应为theta=32.072733877455676。
梯度下降
其中α为learning rate,用来控制梯度下降的幅度。
1 | def gradient_descent(x_, y_, theta_, alpha_, inters_): |
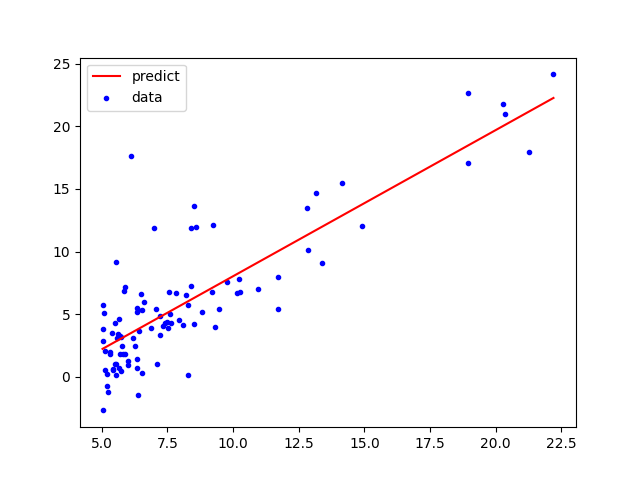
预测函数
设置α以及梯度下降的迭代次数,对θ进行求解。
1 | # 设置参数 |
得出最后的预测函数如下图所示。
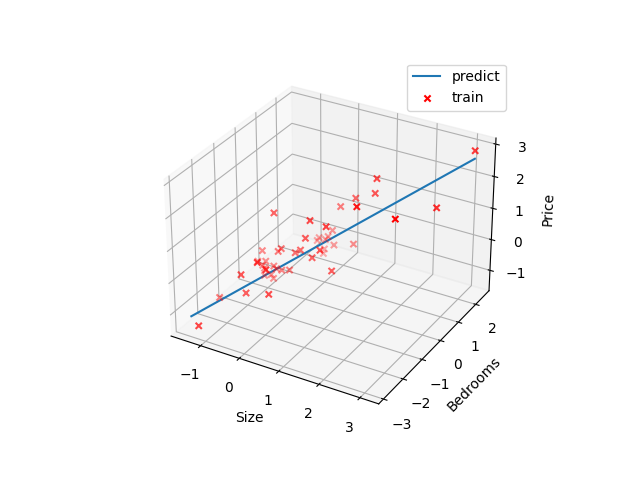
多变量回归问题
在这一部分中,我们将使用多个变量实现线性回归以预测房屋价格。假设你正在出售房屋,并且想知道一个好的市场价格。一种方法是首先收集最近有关出售房屋的信息,并建立房屋价格模型。
文件ex1data2.txt包含某地区房屋价格的训练集。第一列是房屋的大小(以平方英尺为单位),第二列是卧室的数量,第三列是房屋的价格。
读取数据
1 | data2 = pd.read_csv('ex1data2.txt', header=None, names=['Size', 'Bedrooms', 'Price']) |
显示前5行数据如下,
| Size | Bedrooms | Price | |
|---|---|---|---|
| 0 | 2104 | 3 | 399900 |
| 1 | 1600 | 3 | 329900 |
| 2 | 2400 | 3 | 369000 |
| 3 | 1416 | 2 | 232000 |
| 4 | 3000 | 4 | 539900 |
这时我们需要进行均值归一化让数据统一量级,让梯度下降算法更快的收敛。均值归一化就是将每个特征的值减去平均值再除以标准差。
1 | data2 = (data2-data2.mean())/data2.std() |
| Size | Bedrooms | Price | |
|---|---|---|---|
| 0 | 0.130010 | -0.223675 | 0.475747 |
| 1 | -0.504190 | -0.223675 | -0.084074 |
| 2 | 0.502476 | -0.223675 | 0.228626 |
| 3 | -0.735723 | -1.537767 | -0.867025 |
| 4 | 1.257476 | 1.090417 | 1.595389 |
数据处理
1 | data2.insert(0, 'ones', 1) |
梯度下降
1 | g2, cost2 = gradient_descent(x2, y2, theta2, alpha, inters) |
输出结果为[[-1.10892383e-16 8.84042349e-01 -5.24551809e-02]]
特征方程
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:
通过特征方程,解得:
python实现代码如下:
1 | def normal_eqn(x_, y_): # 正规方程 |
梯度下降与正规方程的比较:
梯度下降:需要选择学习率α,需要多次迭代,当特征数量n大时也能较好适用,适用于各种类型的模型
正规方程:不需要选择学习率α,一次计算得出,需要计算逆矩阵,如果特征数量n较大则运算代价大。
下面使用特征方程求解θ与梯度下降的结果进行对比。
1 | print(normal_eqn(x2, y2)) |
结果为如下,可以看出与梯度下降所得的结果很相近。
[[-9.36750677e-17]
[ 8.84765988e-01]
[-5.31788197e-02]]
最后给出预测函数图像: